
I hope you have enjoyed my last post about image data augmentation and now you are comfortable with increasing the size of your small training dataset. Today's post is going to be interesting because we are going to learn how to handle color images and examples of using convolution with keras. Let's starts our learning-
In our first post of this series we have seen that typically an image can be stored in 3-dimensional format- one is for height, one is for width and one is for channels. Colored images have three channels- red,blue,green components. A deep learning network requires that image data should be provided as a 3-D arrays. There are 2 ways to represent the image data as a 3-D array. First way is known as 'channel last' and second way is known as 'channel first'.
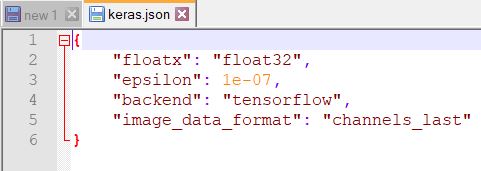
In 'channel last', last channel represents the color channels while in 'channel first', first channel represents the color channels. Please note some deep learning libraries prefer channel first ordering while some prefers last channel ordering. For example If we are using Tensorflow backend with keras then it prefers 'channels last' ordering. If you want to see the configuration file of keras with this setting you need to open keras.json file which resides in your home directory under .keras folder. In my system it is in following path: C:\Users\gupta\.keras and it's look like below-
Let's see how can we use NumPy library to add a channel to a grayscale image?
Grayscale images are loaded as 2-D array so before modeling we need to add a channel dimension to that image. This means we are not adding any new data to the image, infact we are changing the array structure to have an extra axes with one dimension so that it can hold grayscale pixel values. NumPy has expand_dims() function for doing this task. Let's load a color image using Pillow library and see how can we use this function-

Now we will move further and learn about Convolution in computer vision. A convolution is the simple application of a filter to an input that results in an activation. It is a common technique used in CV. Convolution neural networks do not learn a single filter; they learn multiple features in parallel for a given input. For color image filter must always have the same number of channels as the input, also known as depth. If an input image has 3 channels then a filter applied to that image must also have 3 channels. In this case, a 3 × 3 filter would be 3 × 3 × 3 or [3, 3, 3] for rows, columns, and depth.
Let's see a simple example of 1-D Convolution Layer: [0,0,0,1,1,0,0,0]. In this example we have eight elements.Now to use this input in keras we need to pass it as 3 dimension. We can represent this as [1,8,1] where first dimension represents the input sample, second dimension represents length of each sample and third dimension represents no of channels in each sample. So in keras we represent our 1-D convolution layer as below-




In the same way you can use convolution 2-D layer. Here you need to use Conv2D() instead of Conv1D() layer. Also remember in this case input must be 4-dimensional where first dimension defines the samples, second dimension defines the rows, the third dimension defines the columns and the last dimension defines the channels.For in depth knowledge, I would recommend you to read following awesome blog-
https://machinelearningmastery.com/convolutional-layers-for-deep-learning-neural-networks/
That's it for today. We have learnt color channel ordering and basics of convolution in computer vision. Try above examples with 2-D layer and see what changes do you need. In my next post we will learn more about filter and kernel in convolution neural networks. Till then Go chase your dreams, have an awesome day, make every second count and see you later in my next post.
This comment has been removed by the author.
ReplyDeleteGood Information was provided by Dear Data Science.
ReplyDeleteChoosing the Right Web Designing Training A Step by Step Guide